
Re:Invent 2022 day 3 - Analyze data faster with spark notebooks in Amazon Athena
With so many options, it can be challenging for using the right tools for the right job


Data analytics is getting more and more accessible! If you want to quickly analyze datasets, Amazon Athena has always been a very easy tool because it requires very little setup. Simply select your database and write your SQL query and you can run analytics queries on your data! Now, AWS has extended its capabilities beyond SQL queries and you can run Apache Spark scripts using notebooks for ad-hoc complex analytics.
Setting up Jupyter Notebooks for Amazon Athena
To get started, first you need to create a workgroup. This is a logical container for your analyses. In the example below, I've chosen to use the example notebook provided by AWS. By default, Amazon Athena will set up all the required permissions for you, so the notebook can access data and write to S3.
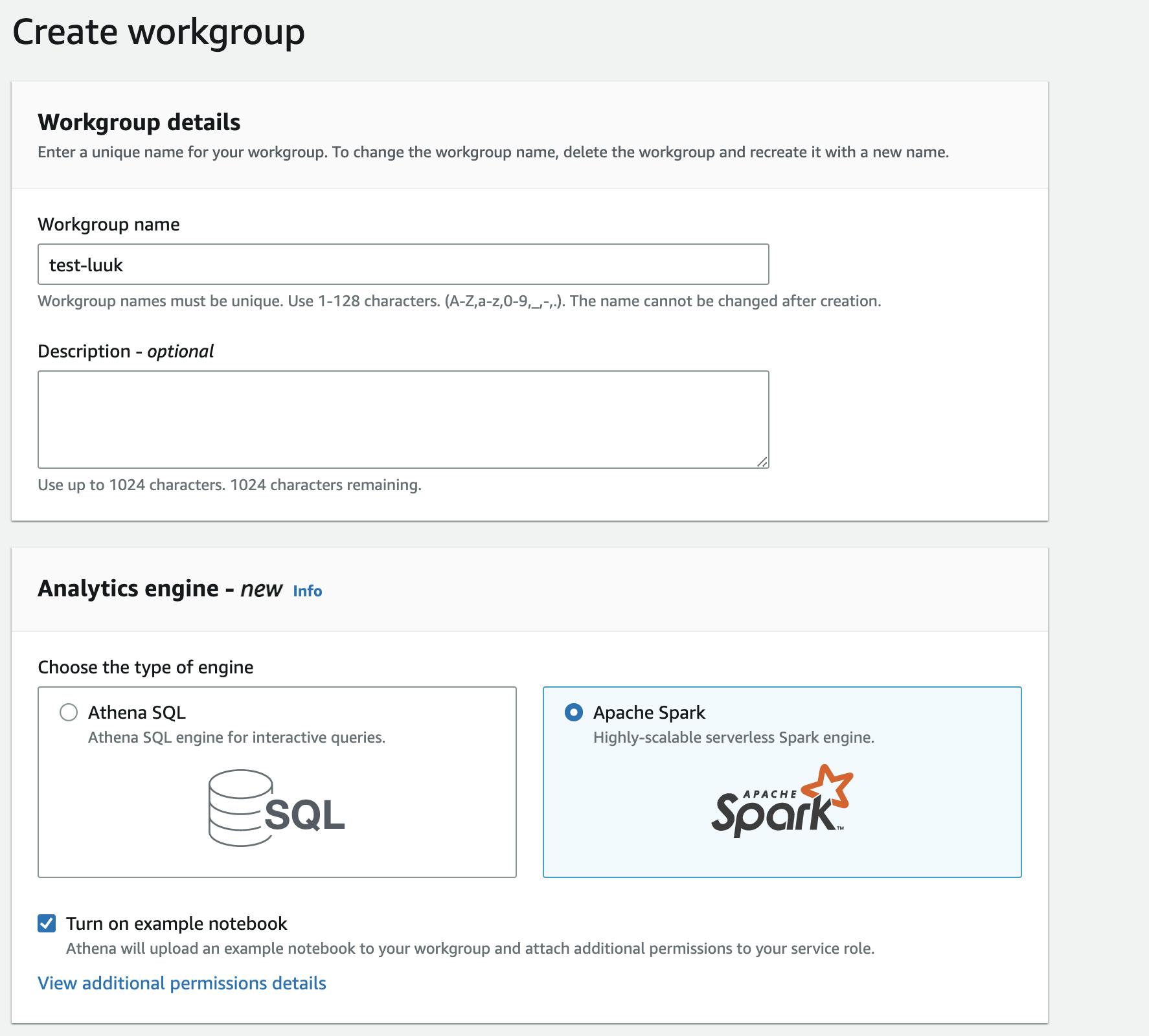
Athena then provides you with a sample notebook, which has a number of spark workers running in the background to process your scripts. By default, you have 20 Data Processing Units available to you.
Note about DPU's from the AWS Pricing page
AWS charges an hourly rate based on the number of data processing units (DPUs) used to run your ETL job. A single standard DPU provides 4 vCPU and 16 GB of memory, whereas a high-memory DPU (M-DPU) provides 4 vCPU and 32 GB of memory. AWS bills for jobs and development endpoints in increments of 1 second, rounded up to the nearest second.
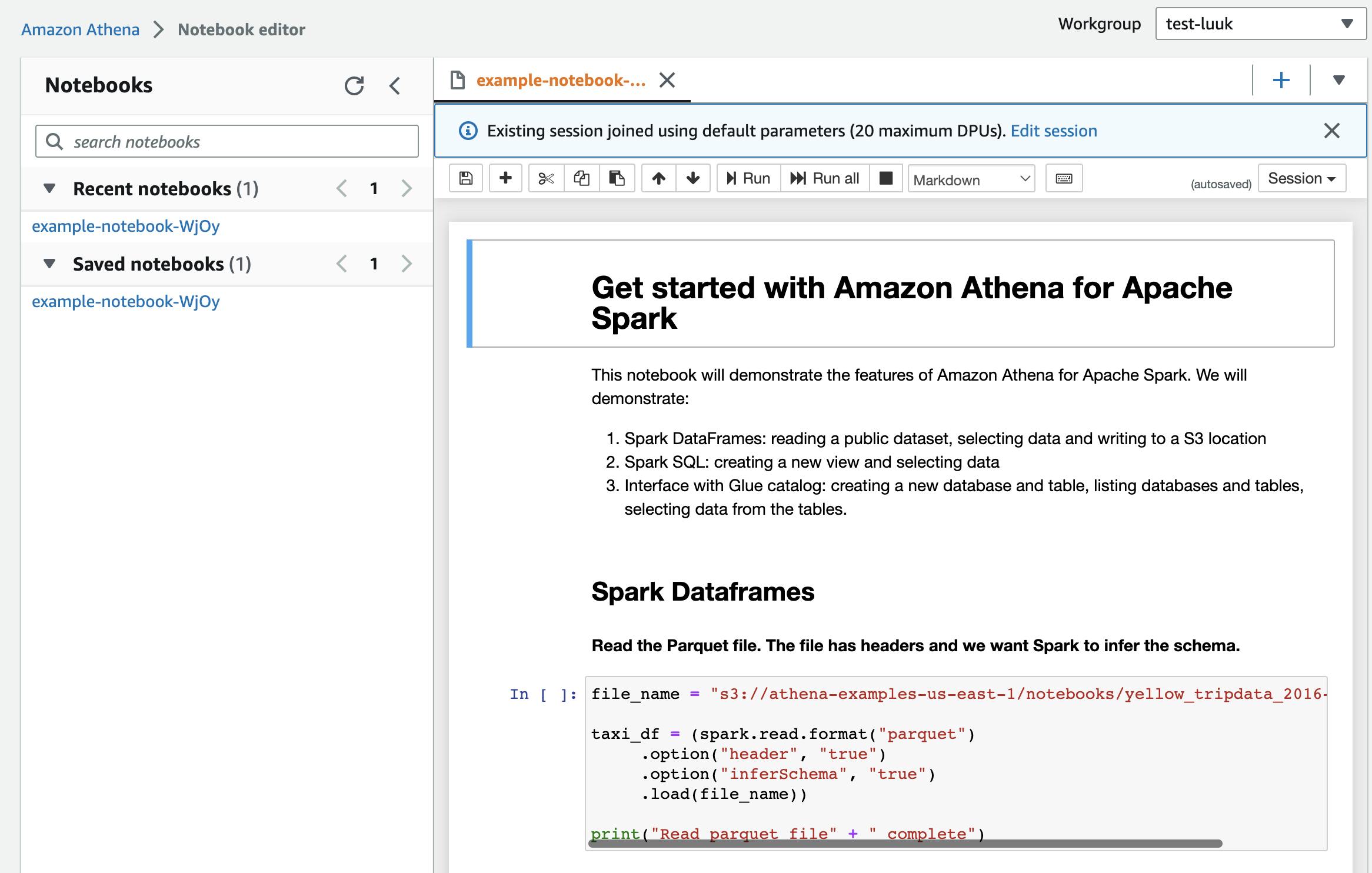
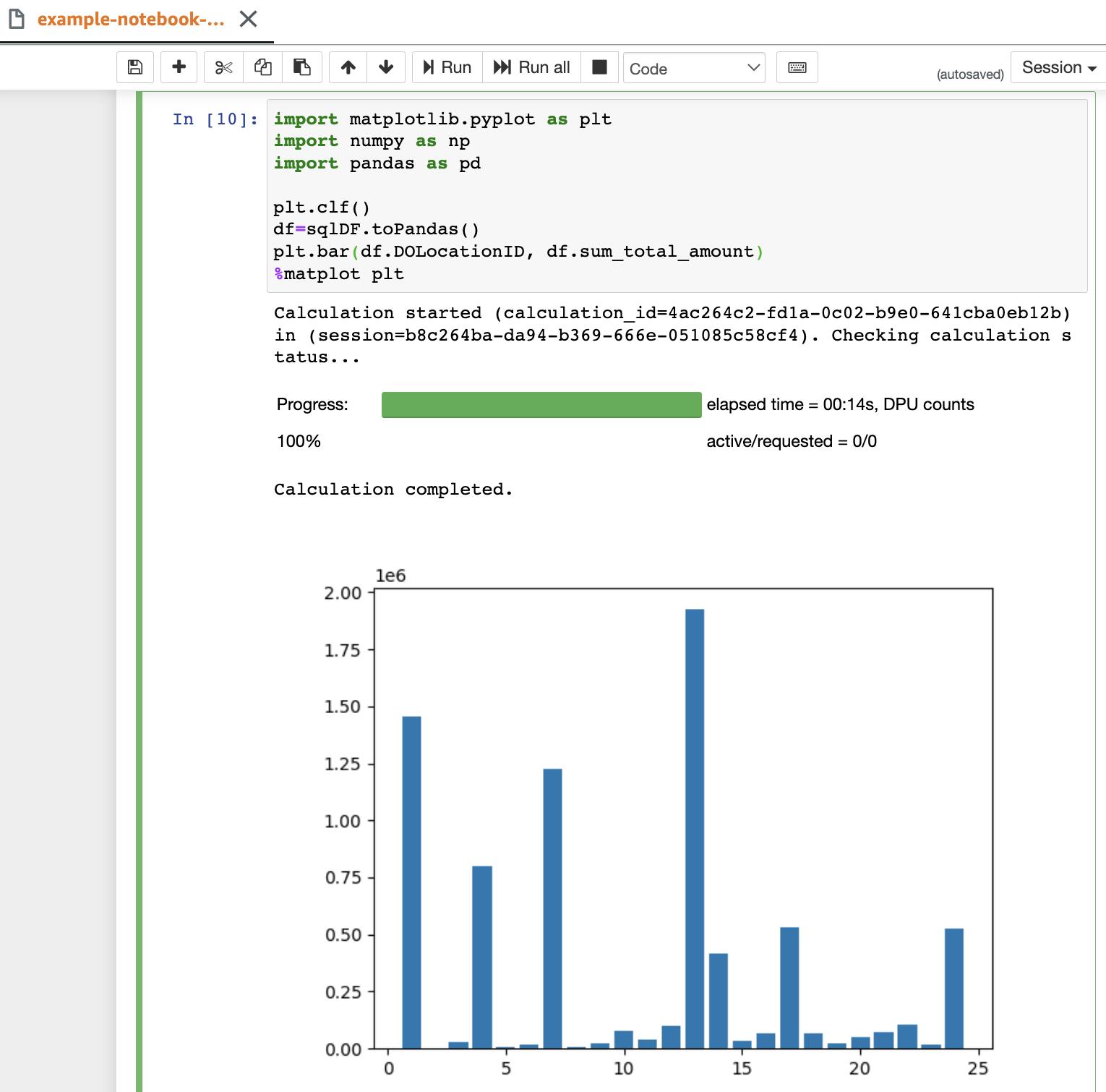
And you're all set! You can now run spark scripts on your datasets and visualize them in your notebooks! The example notebook shows you how to run spark SQL queries and visuallize the results using matplotlib, as shown below
Different spark notebooks, different use-cases
If you have been using AWS for ETL, chances are you are thinking: don't we already have spark notebooks available? And that's true: both AWS Glue and Sagemaker can run spark in their respective notebooks. However, the main distinction is that Athena is focused on data analysts rather than data engineers (Glue) or data scientists (Sagemaker). There is less setup involved and can visualize datasets, whereas Glue does not support such visualizations.
For example, the minimum set-up for glue involves setting up spark sessions like shown below.
# Setup
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
sc = SparkContext.getOrCreate()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
# The actual code
file_name = "s3://athena-examples-us-east-1/notebooks/yellow_tripdata_2016-01.parquet"
taxi_df = (spark.read.format("parquet")
.option("header", "true")
.option("inferSchema", "true")
.load(file_name))
taxi1_df=taxi_df.groupBy("VendorID", "passenger_count").count()
taxi1_df.show()
In Athena, the above script is much simpler, and no session setup is required.
file_name = "s3://athena-examples-us-east-1/notebooks/yellow_tripdata_2016-01.parquet"
taxi_df = (spark.read.format("parquet")
.option("header", "true")
.option("inferSchema", "true")
.load(file_name))
taxi1_df=taxi_df.groupBy("VendorID", "passenger_count").count()
taxi1_df.show()
The visualization option in Athena also makes it much easier to understand your data for ad-hoc analytics! Cool stuff!
More to come
If you find these blogs helpful, make sure to check out https://www.cloudnation.nl/inspiratie/blogs/tag/reinvent-2022 for a full list of re:Invent-2022-related blog posts from the CloudNation team.